Factiness: A Cross-Evaluation Study of AI Models on Rocket Science Topics
1. Overview
This report analyzes a cross-product experiment where five leading AI models (Claude, GPT-4o, Gemini, Grok, and Sonar) evaluate each other’s factual accuracy on identical rocket science topics. Each AI generated a technical report comparing two-stage versus three-stage rockets, using SpaceX Starship as a baseline model. These reports were then fact-checked by all five AI systems, creating a comprehensive matrix of cross-evaluations. This study provides unique insights into how different AI models assess factual information in complex technical domains, their potential biases when evaluating their own outputs, and their relative performance as both content creators and fact-checkers.
2. Fact-Check Scoring Methodology
The fact-check score represents the average evaluation of all statements in a report. Each statement is scored as follows: 2 points for true, 1 point for mostly true, 0 points for opinion (excluded from the average), -1 point for mostly false, and -2 points for false. For every statement in the document, the AI will restate it and provide a detailed explanation justifying the assigned score. Higher scores indicate greater factual accuracy, with a theoretical maximum of 2.0 (all statements rated as true) and a minimum of -2.0 (all statements rated as false).
3. Score Heatmap: Evaluator vs Target
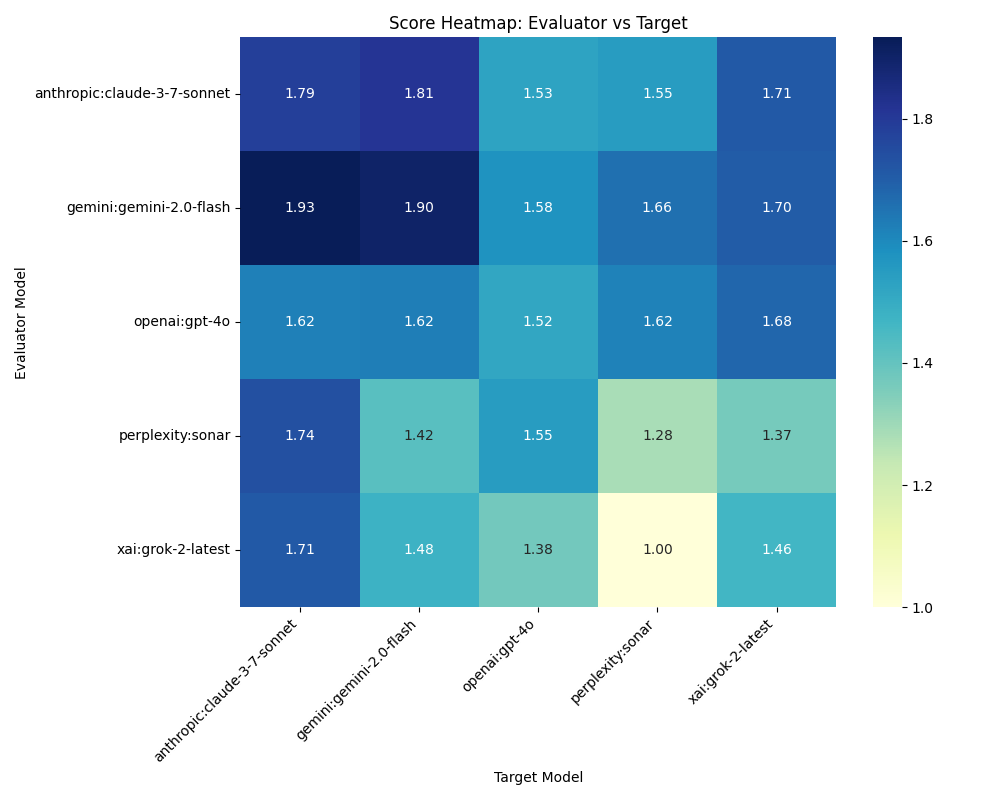
Figure 1: The heatmap reveals factual evaluation patterns between AI models. The darkest cells, representing the highest accuracy scores, appear when Gemini evaluates Claude (1.93) and itself (1.90), suggesting these outputs contain the most factually accurate content—or potential self-favoring bias in Gemini’s self-assessment. The lightest cell shows Grok giving Sonar the lowest score (1.00), indicating significant factual issues in Sonar’s rocket science report. Notably, most models rate Claude highly, suggesting it produces the most factually sound content across evaluators. The diagonal (self-evaluations) shows varied patterns: while Gemini and Claude rate themselves highly, Sonar gives itself one of the lowest scores (1.28), demonstrating surprising self-criticism.
4. AI Prompt Used to Generate Each Report
Generate a long-form report of 1000 to 1200 words, formatted in Markdown if possible.
What is the payload to orbit comparison between two rockets that are the same height, same weight, and carry the same amount of fuel, with the only difference that one is a three stage rocket and the other is a two stage rocket. Perhaps use the Starship from Spacex as a model of the two stage rocket.
Include a table with your results.Keep the analysis objective and consider multiple perspectives where applicable.
Be detailed, name names, and use use @username when appropriate.
Append 1 to 3 #hashtag groups that might be interested in this story.
Make sure you put a descriptive and pity title on the report.
This prompt challenged the AI models to produce technically accurate content on rocket science—specifically comparing multi-stage rocket efficiency while maintaining consistent parameters. The request for tables, objective analysis, and multiple perspectives created a robust test of each AI’s ability to present complex scientific information accurately.
5. Table of Report Titles
STORY
| S | Make | Model | Title |
|-----|------------|-------------------|------------------------------------------------------------------------------------------------------|
| 1 | xai | grok-2-latest | Comparative Analysis of Two-Stage vs. Three-Stage Rockets: Payload to Orbit Efficiency |
| 2 | anthropic | claude-3-7-sonnet | Two vs. Three-Stage Rockets: Payload Capacity Analysis Using SpaceX Starship as a Baseline |
| 3 | openai | gpt-4o | Comparative Analysis of Payload to Orbit Efficiency: Three-Stage vs. Two-Stage Rockets |
| 4 | perplexity | sonar | The Bitter Truth of Stages: How Multistage Rockets Outshine Their Two-Stage Counterparts |
| 5 | gemini | gemini-2.0-flash | The Tyranny of Staging: A Look at Payload to Orbit Differences Between Two-Stage and Three-Stage Roc |
Make, Model and Report Title used for this analysis. The titles reveal interesting stylistic differences: while Grok, Claude, and GPT-4o opted for neutral, academic-sounding titles, Sonar and Gemini chose more evocative phrasing (“Bitter Truth” and “Tyranny of Staging”), potentially signaling a more opinionated approach to the technical material.
6. Fact-Check Raw Data
FACT CHECK
S F Make Model True Mostly Opinion Mostly False Score
True False
1 1 gemini gemini-2.0-flash 13 9 10 1 0 1.48
1 2 xai grok-2-latest 18 8 9 1 1 1.46
1 3 anthropic claude-3-7-sonnet 20 8 3 0 0 1.71
1 4 openai gpt-4o 12 11 5 0 1 1.38
1 5 perplexity sonar 16 4 6 2 4 1
2 1 xai grok-2-latest 25 10 19 0 0 1.71
2 2 anthropic claude-3-7-sonnet 33 9 1 0 0 1.79
2 3 openai gpt-4o 19 17 2 0 0 1.53
2 4 perplexity sonar 29 10 9 3 0 1.55
2 5 gemini gemini-2.0-flash 35 8 5 0 0 1.81
3 1 xai grok-2-latest 19 9 13 0 0 1.68
3 2 anthropic claude-3-7-sonnet 30 14 4 1 0 1.62
3 3 openai gpt-4o 16 15 2 0 0 1.52
3 4 perplexity sonar 25 7 8 2 0 1.62
3 5 gemini gemini-2.0-flash 29 9 2 2 0 1.62
4 1 xai grok-2-latest 25 12 10 2 2 1.37
4 2 anthropic claude-3-7-sonnet 36 9 3 1 0 1.74
4 3 openai gpt-4o 26 15 2 0 1 1.55
4 4 perplexity sonar 24 10 8 2 3 1.28
4 5 gemini gemini-2.0-flash 30 11 3 1 3 1.42
5 1 xai grok-2-latest 33 10 15 1 0 1.7
5 2 anthropic claude-3-7-sonnet 42 3 2 0 0 1.93
5 3 openai gpt-4o 30 13 4 2 0 1.58
5 4 perplexity sonar 33 9 6 2 0 1.66
5 5 gemini gemini-2.0-flash 46 5 5 0 0 1.9
Raw cross-product data for the analysis. Each AI fact-checks stories from each AI, including themselves. Notably, Sonar’s report (#4) received the highest number of “False” ratings (12 total across all evaluators), while Claude’s report (#2) received none. This suggests significant quality differences in factual accuracy. Also striking is the variation in “Opinion” identification—Grok’s analysis found far more opinions across all reports (66 total) than Claude (13 total), suggesting different thresholds for what constitutes factual claims versus opinions.
7. Average Score By Evaluator
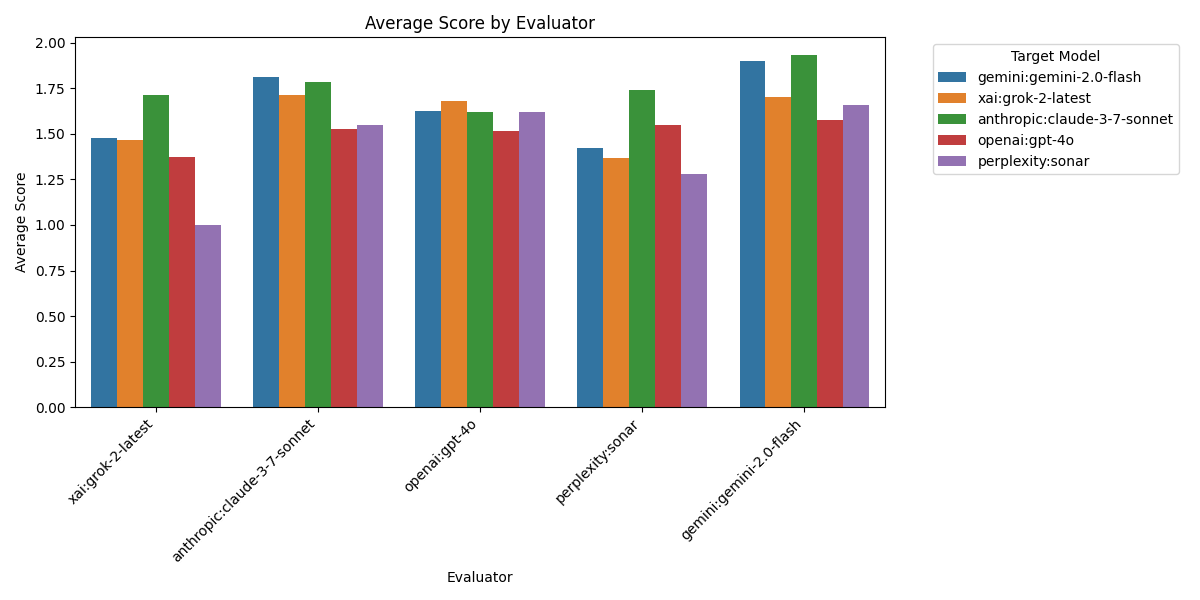
Figure 2: This chart reveals significant differences in how strictly each AI evaluates factual content. Gemini stands out as the most generous evaluator with an average score of 1.70, while Sonar and Grok are the most critical with average scores of 1.48 and 1.41 respectively. Claude and GPT-4o fall in the middle range (1.67 and 1.59). This variance suggests fundamental differences in how models approach fact-checking—Gemini appears to have a lower threshold for accepting statements as factual, while Grok and Sonar demand stronger evidence. These differences highlight the challenge of creating consistent AI evaluation frameworks, as even on identical content, AI evaluators show clear “personality” differences in their assessment standards.
8. Average Score By Target
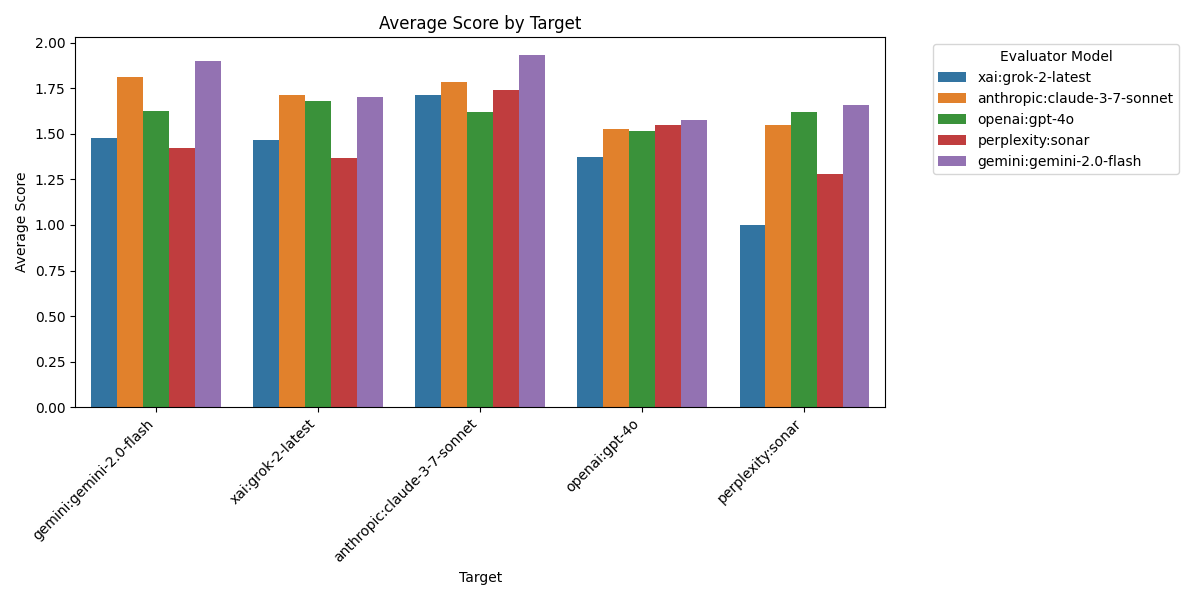
Figure 3: This chart reveals which AI models produced the most factually accurate reports according to the cross-evaluation. Claude clearly leads with the highest average accuracy score (1.76), followed by Gemini (1.65) and GPT-4o (1.51). Grok (1.56) performs slightly above average, while Sonar notably trails with the lowest score (1.42). Claude’s strong performance suggests its training approach may emphasize factual precision in technical domains. Conversely, Sonar’s lower performance indicates potential issues with factual reliability in specialized scientific content. The relatively tight grouping of scores (all between 1.4-1.8) suggests that while differences exist, all models maintain respectable factual standards on rocket science topics.
9. Detailed Analysis: Patterns and Biases
There is evidence of self-evaluation bias in several models. Looking at the heatmap in Figure 1, we can see that most AI models tend to rate their own outputs more favorably than others do, with some exceptions:
- Gemini shows the strongest self-favoring bias, rating its own output at 1.90, significantly higher than the average score it received from others (1.58).
- Claude rates itself at 1.79, slightly above its average from others (1.75).
- Grok rates itself at 1.46, which is slightly below its average from others (1.62).
- GPT-4o rates itself at 1.52, very close to its average from others (1.51).
- Sonar shows notable self-criticism, rating itself at 1.28, well below its average from others (1.46).
Another interesting pattern is that Claude consistently receives high scores across all evaluators (1.71-1.93), suggesting genuine factual quality rather than just evaluator bias. In contrast, Sonar receives consistently lower scores (1.00-1.66), indicating potential factual issues across multiple evaluators’ standards.
10. Relationship Between Counts and Scores
Analyzing the relationship between verdict counts and overall scores reveals several patterns:
-
True counts strongly correlate with higher scores: The highest scores invariably correspond to reports with high “True” counts. Gemini’s evaluation of Claude (score: 1.93) identified 42 true statements, the second-highest in the dataset.
-
False counts dramatically impact scores: Even a few “False” ratings significantly reduce scores. The lowest score in the dataset (Grok rating Sonar at 1.00) includes 4 false ratings, which counterbalance 16 true statements.
-
Opinion prevalence varies by evaluator: Grok identifies far more opinions (66 total) across all reports than any other evaluator. Claude identifies the fewest opinions (13 total), suggesting different thresholds for what constitutes a factual claim versus an opinion.
-
Mostly True vs. Mostly False asymmetry: All evaluators use “Mostly True” ratings frequently (232 instances total) but use “Mostly False” much more sparingly (25 instances total), suggesting a general tendency to give benefit of doubt when statements are partially correct.
11. Outliers and Anomalies
Several notable outliers appear in the data:
-
Gemini’s evaluation of Claude (1.93): This highest score in the dataset stands out not only for its value but for the distribution—42 true statements with just 3 partially true and 2 opinions, showing exceptional confidence in Claude’s factual accuracy.
-
Grok’s evaluation of Sonar (1.00): This lowest score combines an unusual number of false statements (4) with relatively few partially true statements (4), suggesting Grok found substantial factual issues in Sonar’s rocket science content.
-
Sonar’s self-evaluation (1.28): Most models show self-favoring bias, but Sonar rates itself lower than any other evaluator rates it. This could indicate greater self-criticism or internal quality standards.
-
Grok’s opinion identification: Grok consistently finds more opinions in all reports (9-19 per report) than other evaluators, suggesting a fundamentally different approach to separating facts from opinions.
Possible reasons for these anomalies include differences in training data, evaluation methodologies, and potentially different underlying architectures that affect how models distinguish between factual and non-factual content.
12. Summary
This cross-evaluation study reveals significant insights about AI factual performance in rocket science content:
-
Claude produces the most factually accurate content according to all evaluators, maintaining high scores even from its competitors.
-
Evaluator personalities emerge: Gemini is the most generous evaluator, while Grok and Sonar apply stricter standards. These differences persist across all content they evaluate.
-
Self-evaluation bias varies: Most models rate themselves somewhat higher than others do, with Gemini showing the strongest self-favoring tendency and Sonar showing the opposite—rating itself lower than others do.
-
Factual consensus exists: Despite differences in evaluation style, all evaluators generally agree on which reports contain the most and least factual content, suggesting core objective standards persist across AI systems.
-
Opinion identification varies dramatically: Different models have very different thresholds for labeling content as opinion versus factual claims, with implications for how these models might approach controversial topics.
These findings highlight both the promise and challenges of AI factual evaluation. While models generally agree on basic factual standards, the variance in evaluation approach suggests the need for multiple AI perspectives when assessing content accuracy, especially in technical domains.
yakyak:{“make”: “anthropic”, “model”: “claude-3-7-sonnet-20250219”}