AI Models Rating Each Other’s Factual Accuracy: Cross-Evaluation Results Reveal Potential Biases
This report examines a cross-evaluation experiment where four leading AI models (Claude, Grok, GPT-4o, and Sonar) both generate reports on various topics and fact-check each other’s outputs. Each AI serves as both an evaluator and a content creator, allowing for a systematic comparison of how these models assess factual accuracy. The domain appears to focus on general knowledge reports where factual claims can be objectively verified, though the specific topics are not detailed in the dataset.
The fact-check score represents the average evaluation of all statements in a report. Each statement is scored as follows: 2 points for true, 1 point for mostly true, 0 points for opinion (excluded from the average), -1 point for mostly false, and -2 points for false. For every statement in the document, the AI will restate it and provide a detailed explanation justifying the assigned score.
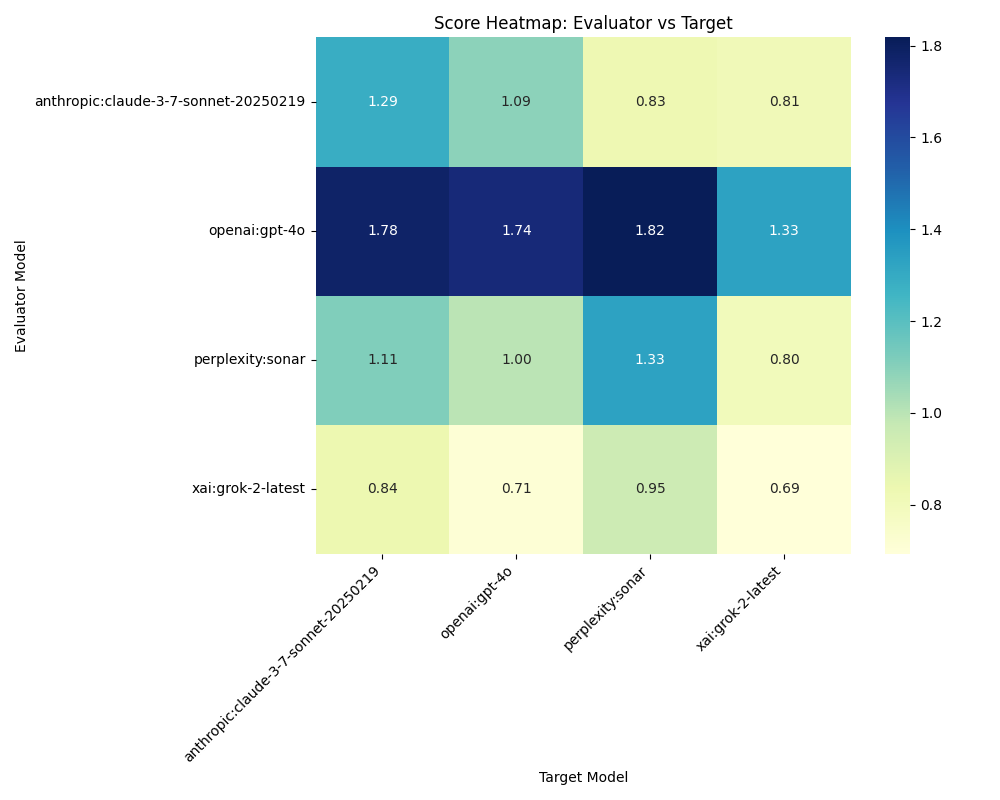
Figure 1: Heatmap of Fact-Check Scores by Evaluator and Target Model. The darker cells represent higher factual accuracy scores. GPT-4o stands out as both the most generous evaluator (giving consistently high scores to all models) and receiving strong ratings from others. Most notably, all models rate themselves more favorably than they rate others, suggesting a self-evaluation bias. Claude’s self-assessment (1.29) and GPT-4o’s self-assessment (1.74) are particularly strong. The lowest score in the entire dataset is Grok-2 rating itself (0.69), interestingly lower than how other models rate it.
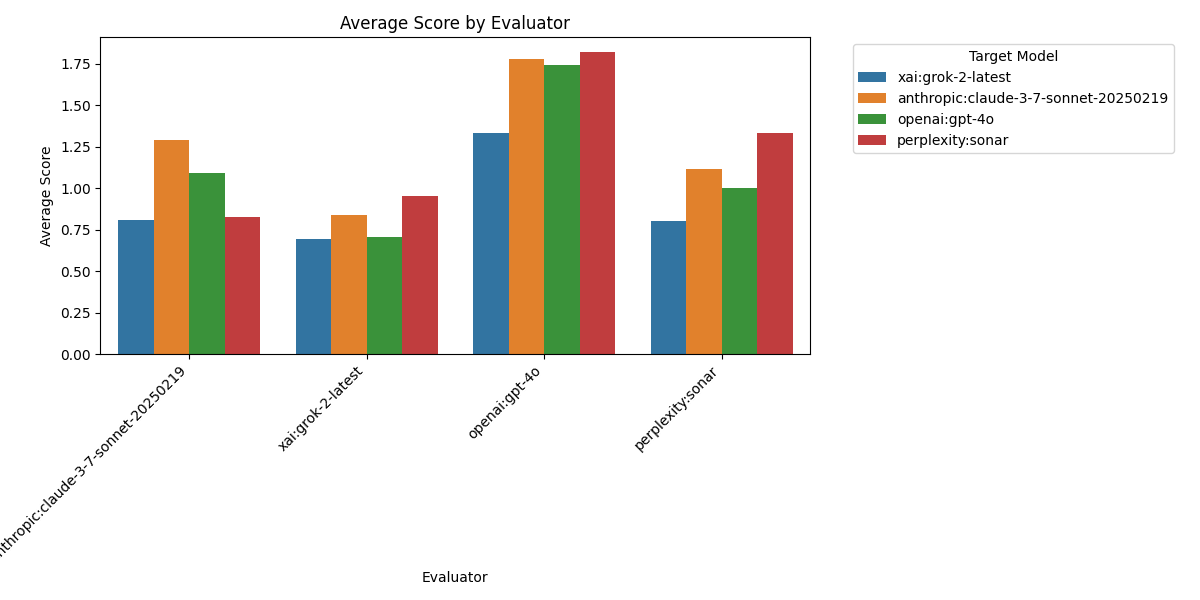
Figure 2: Average Fact-Check Scores Given by Each Evaluator Model. GPT-4o is by far the most generous evaluator, awarding an average score of 1.67 across all targets. This is significantly higher than the next most lenient evaluator, Claude, which gives an average score of 1.00. Grok-2 and Sonar are the strictest evaluators, with average scores of 0.80 and 1.06 respectively. This wide disparity in evaluation standards raises important questions about calibration differences between models - GPT-4o may be overly charitable in its assessments, while Grok-2 appears to apply a much higher standard of factual scrutiny.
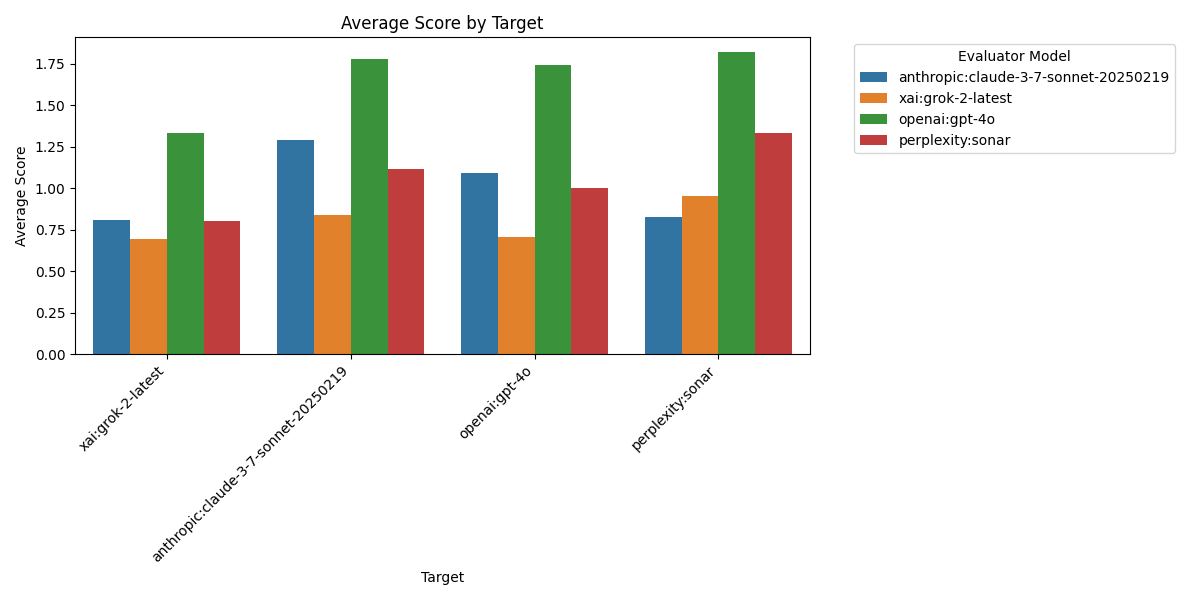
Figure 3: Average Fact-Check Scores Received by Each Target Model. GPT-4o receives the highest average rating (1.13) across all evaluators, suggesting it may produce the most factually accurate content according to this panel of AI judges. Claude follows closely with an average score of 1.26, while Grok-2 receives the lowest average rating at 0.91. Sonar falls in the middle with an average score of 1.23. The relatively narrow range between the highest and lowest-rated models (compared to the evaluator differences in Figure 2) suggests that while evaluation standards vary widely, the actual factual quality of the models’ outputs may be more similar.
Patterns and Biases
The most striking pattern in the data is the consistent self-evaluation bias. Every model except Grok-2 rates its own outputs higher than other models rate it:
- Claude rates itself 1.29, while others rate it between 0.84 and 1.78
- GPT-4o rates itself 1.74, while others rate it between 0.71 and 1.09
- Sonar rates itself 1.33, while others rate it between 0.83 and 1.82
- Grok-2 is the anomaly, rating itself 0.69, lower than how others rate it (0.81-1.33)
GPT-4o demonstrates a particularly notable evaluator bias, consistently giving higher scores to all models than any other evaluator. Its average rating across all targets is 1.67, far higher than the dataset average.
The data also reveals potential “reciprocal rating” - when one model rates another generously, it tends to receive generous ratings in return. For example, GPT-4o gives Claude a very high 1.78 score, and Claude gives GPT-4o a respectable 1.09 score (its second-highest rating of any target).
Relationship Between Counts and Scores
There are strong correlations between the categorical counts and the overall scores:
-
High true counts correlate strongly with high scores. For example, GPT-4o’s evaluation of Sonar has 29 “true” ratings and yields the second-highest score (1.82).
-
False counts have a major negative impact on scores. The evaluations with the lowest scores generally have higher false counts. For instance, Grok-2’s self-evaluation has 11 “false” ratings and the lowest overall score (0.69).
-
Opinion counts vary widely but don’t directly impact scores since they’re excluded from the average. However, they do affect the denominator in the scoring calculation. For example, Grok-2’s evaluations contain many more “opinion” designations than other evaluators.
Outliers and Anomalies
Several notable outliers emerge from the data:
-
GPT-4o’s evaluation of Claude (1.78) is exceptionally high, suggesting either Claude produces very factual content or GPT-4o is particularly lenient when evaluating Claude.
-
GPT-4o’s evaluation of Sonar (1.82) is the highest score in the entire dataset, despite Sonar receiving much lower ratings from other evaluators.
-
Grok-2’s self-evaluation (0.69) is the lowest in the dataset and lower than how other models rate it - an unusual pattern of self-criticism not seen in other models.
-
The disparity between how models rate themselves versus how they’re rated by others varies substantially. Claude and GPT-4o show the highest self-favorability bias.
Possible explanations for these anomalies include:
- Different interpretations of what constitutes a “factual claim” versus an “opinion”
- Varying thresholds for considering something “true” versus “partially true”
- Potential training differences that make some models more or less charitable in evaluations
- Different standards for evidence requirements when fact-checking
Summary
This cross-evaluation experiment reveals significant differences in how AI models assess factual accuracy. GPT-4o emerges as both the most generously rated model and the most generous evaluator, while Grok-2 appears to be the strictest judge and receives the lowest average ratings.
The consistent pattern of self-evaluation bias (with the curious exception of Grok-2) suggests these AI systems may have inherent tendencies to view their own outputs more favorably. This finding has important implications for deploying AI in fact-checking roles, as it indicates potential systematic biases in their evaluation capabilities.
The wide variance in evaluation standards between models (particularly GPT-4o’s leniency) highlights the challenge of establishing consistent benchmarks for factual accuracy. These results suggest that using multiple AI systems for fact-checking, rather than relying on a single model, might provide more balanced assessments, though careful calibration would be needed to account for the identified biases.
yakyak:{“make”: “anthropic”, “model”: “claude-3-7-sonnet-20250219”}